Vous avez déjà entendu parler des « logits » ? Si ce n’est pas le cas, préparez-vous à lire un post plus technique sur le fonctionnement des LLM en coulisses et sur la façon dont ils effectuent l’inférence pour choisir le prochain mot (en réalité le prochain token) dans la phrase qu’ils sont en train de générer.
De manière très directe, les logits sont les scores bruts, “purs” et non normalisés générés par la couche de projection linéaire finale du réseau neuronal d’un modèle d’IA.
Pour revenir au commencement, lorsque vous entraînez un LLM à partir de zéro, vous effectuez la tokenisation (la séparation des mots de votre corpus d’entraînement en tokens, ou morceaux de mots, comme les tokens « in » et « feliz » qui composent le mot « infeliz »). Cette étape précède l’entraînement du réseau, et vous entraînez le tokeniseur sur le corpus pour définir un vocabulaire fixe, qui varie généralement entre 50 000 et plus de 100 000 tokens. Prenons 100 000 pour notre exemple.
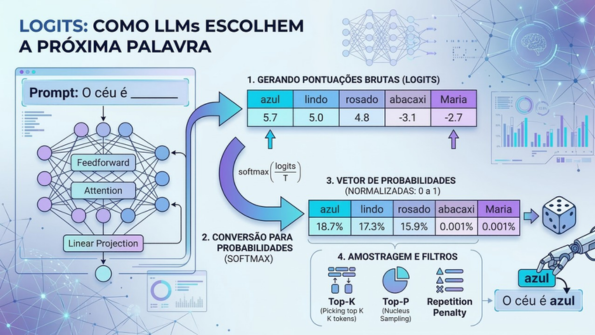
Lorsque vous envoyez une invite, un modèle instructionné va tenter de la “terminer” en fournissant une réponse. Pour faire simple, prenons l’exemple de la complétion d’une phrase. Supposons la phrase : Le ciel est ____. Le LLM va traiter cette information à travers des dizaines de blocs d’attention et de feedforward (le cœur du Transformer), et, au final, une couche de projection linéaire déverse un vecteur de 100 000 logits, correspondant exactement à la taille de notre vocabulaire. Autrement dit, il attribue une note brute à chacun des 100 000 tokens qu’il connaît dans son dictionnaire, évaluant lequel serait le plus logique à suivre.
Exemple hypothétique de logits pour le prochain token de « Le ciel est ____ » :
["bleu" = 5.7,
"joli" = 5.0,
"ananas" = -3.1,
...,
"Maria" = -2.7,
"rosé" = 4.8,
...]
Comme les logits ne sont pas limités à 0 et 1, l’entraînement par descente de gradient peut fonctionner de manière numériquement plus stable (éviter les valeurs extrêmement petites). Toutefois, ces valeurs brutes ne sont pas intuitives pour nous, donc, au final, on applique une fonction mathématique appelée Softmax, qui transforme ces valeurs en pourcentages allant de 0 à 100 %. Dans notre exemple ci-dessus, cela pourrait donner :
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B")
inputs = tokenizer("Le ciel est", return_tensors="pt")
with torch.no_grad():
output = model(**inputs)
next_token_logits = output.logits[0, -1, :]

Mais avant d’appliquer cette Softmax, le système peut manipuler mathématiquement ces logits pour contrôler la façon dont le modèle écrit. Le paramètre le plus célèbre pour ce faire est la Température. La formule est en gros softmax(logits/Température), soit :
-
Si vous utilisez une Température Basse (par ex. 0,1), les logits sont divisés par 0,1, ce qui équivaut à les multiplier par 10. Cela amplifie radicalement la différence entre les scores, rendant l’IA plus conservatrice, factuelle et prévisible (le logit de « bleu » va écraser tous les autres).
-
Avec une Température élevée (par ex. 1,5), la division atténue les différences et les scores se rapprochent les uns des autres (l’IA aura plus tendance à donner une chance à des mots moins évidents), ce qui la rend beaucoup plus créative et variée, mais avec un risque accru d’alucinations.
C’est aussi à ce moment-là qu’entrent en jeu des filtres célèbres tels que le Top-K (où le modèle ignore des milliers de logits faibles et ne retient que les K valeurs les plus élevées). Puis, dans l’espace de probabilités (après le Softmax), apparaît le Top-P, aussi appelé échantillonnage par nucléus, qui ne sélectionne que les tokens dont les probabilités cumulées atteignent un seuil (par ex. 90 %). D’autres filtres tels que le Repetition Penalty (qui pénalise les tokens déjà générés pour éviter les répétitions) peuvent aussi être appliqués.
Après tout cela, l’IA “fait rouler les données”, choisit le token, l’ajoute au texte et recommence le cycle. Ce processus auto-régressif se répète des dizaines, voire des centaines de fois par seconde jusqu’à ce que la réponse soit complète.
Si vous faites tourner des modèles localement avec des outils comme Ollama, LM Studio, llama.cpp ou text-generation-webui, vous avez probablement déjà vu ces paramètres exposés dans l’interface ou en ligne de commande. Maintenant, vous savez exactement ce qu’ils font en coulisses : ils manipulent les logits avant (ou après) le Softmax pour contrôler le comportement du modèle.
En utilisant la bibliothèque Transformers de HuggingFace, il est possible de voir directement les logits :
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B")
inputs = tokenizer("Le ciel est", return_tensors="pt")
with torch.no_grad():
output = model(**inputs)
next_token_logits = output.logits[0, -1, :]C’est ce vecteur « next_token_logits » qui contient le score de chaque token du vocabulaire. Dans la pratique, le « model.generate() » fait tout cela en boucle pour vous, en appliquant automatiquement les paramètres de température, top_k, top_p et repetition_penalty à chaque étape avant de choisir le prochain token.
Et c’est à peu près tout ! 🙂 Savoir comment la mécanique est faite en coulisses aide énormément à « apprivoiser » ces IA.

