Dans de nombreuses entreprises, la discussion sur l’architecture des données commence par l’outil. Quelqu’un demande si l’entrepôt de données tient encore le coup. Un autre défend le lakehouse. Un troisième évoque le catalogue, la couche sémantique, les pipelines modernes, le streaming, les notebooks, la plateforme d’IA et une autre liste de solutions qui semblent promises à l’avenir.
Tout cela peut être important. Mais, bien souvent, la question arrive trop tôt.
Parce que si personne ne sait exactement ce que signifie un champ, qui en est le propriétaire, qui en dépend, à quelle fréquence il devrait être mis à jour et ce qui se passe quand il change, changer d’architecture ne résout pas le problème. Cela ne fait que déplacer le lieu où réside la confusion.
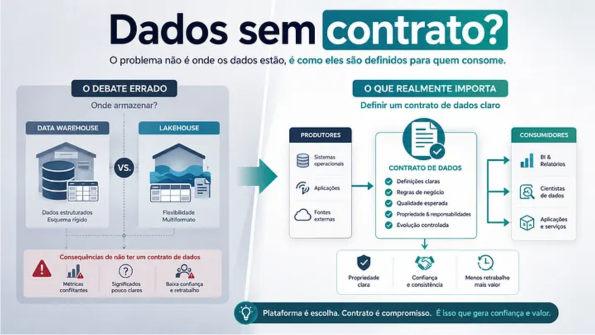
L’erreur de nombreuses initiatives de données n’est pas de choisir lakehouse ou warehouse. C’est de modéliser les données sans contrat de consommation.
Avant la plateforme, il y a le contrat. Avant l’outil, il y a la sémantique. Avant le tableau de bord, il y a la confiance.
Le débat erroné: l’outil avant le contrat
Lakehouse, warehouse, data lake, couche sémantique, catalogue, orchestrateur, moteur de traitement, outil de BI. Tous ces éléments peuvent jouer un rôle important dans une architecture de données mature.
Le problème se produit lorsque l’organisation discute de la pile comme si elle pouvait résoudre seule les problèmes de signification, de confiance et de responsabilité.
Une plateforme moderne peut stocker, traiter et rendre les données accessibles à grande échelle. Mais elle ne répond pas automatiquement à des questions telles que :
- Que signifie ce champ ?
- Qui est le propriétaire de ce dataset ?
- Quels consommateurs en dépendent ?
- Quelles est l’attente en matière de mise à jour ?
- Quel niveau de qualité est acceptable ?
- Qu’est-ce qui constitue une rupture de contrat ?
- Comment les changements sont-ils communiqués ?
Sans ces réponses, même l’architecture la plus sophistiquée devient une base coûteuse qui engendre des doutes plus rapidement.
C’est une erreur fréquente : améliorer les canalisations sans s’accorder sur le type d’eau qui doit y circuler.
Qu’est-ce qu’un contrat de données en pratique
Le contrat des données n’a pas besoin de commencer comme un processus lourd. En essence, il s’agit d’un accord explicite entre celui qui publie et celui qui consomme les données.
Cet accord définit ce qui est livré, sous quel format, avec quelle signification, quelle est l’attente de qualité et quelles règles d’évolution s’appliquent.
Un contrat simple peut inclure :
- Nom du dataset
- Propriétaire
- Schéma attendu
- Signification des champs
- Champs obligatoires
- Valeurs autorisées
- Fréquence de mise à jour
- Consommateurs connus
- Règles pour les changements majeurs
- Attentes de qualité
Un exemple simple :
dataset: orders_daily
owner: data-commerce
refresh: daily
primary_key: order_idfields:
order_id:
type: string
required:true
total_amount:
type: decimal
required:true
description: Valor final do pedido após descontos
status:
type: string
accepted_values:
- created
- paid
- canceled
- refunded
consumers:
- finance-bi
- growth-analytics
breaking_changes:
notice_period_days:15Le point n’est pas le YAML. Le point, c’est la clarté.
Sans contrat, le consommateur doit deviner. Avec le contrat, il sait ce à quoi il peut s’attendre, qui contacter, comment les changements se produisent et quelles garanties existent.
Le problème de la sémantique invisible
L’un des plus grands problèmes dans les données n’est pas technique. Il est sémantique.
Deux domaines peuvent employer le même mot pour signifier des choses différentes. Ou, pire encore, employer des mots différents pour parler de la même chose.
Un exemple classique: « recette ».
Pour le département financier, « recette » peut signifier la valeur reconnue après les ajustements comptables. Pour la croissance, cela peut signifier des commandes payées. Pour le produit, cela peut signifier des commandes terminées. Pour les ventes, cela peut signifier des commandes créées avant annulation.
Tous peuvent être « corrects » dans leur propre contexte. Mais si cette différence n’est pas explicite, l’entreprise commence à fonctionner avec plusieurs vérités.
D’où émergent les symptômes connus :
- Tableaux de bord affichant des chiffres différents
- Des réunions coûteuses à discuter de quelle métrique est correcte
- Des décisions retardées par manque de confiance
- Rédémarrage dans les analyses
- Des équipes créant des feuilles de calcul parallèles
- Des domaines cessant de faire confiance à la plateforme officielle de données
La stack peut être moderne. Le problème reste ancien: l’absence de contrat sémantique.
Des données sans propriétaire deviennent un risque organisationnel
Un autre point critique : des données sans propriétaire deviennent un passif.
Lorsqu’un dataset n’a pas de propriétaire clairement identifié, personne ne répond à la qualité, à l’évolution, à la signification ou à l’impact d’un changement. Il peut être utilisé par des dizaines de consommateurs, mais il continue d’opérer comme un artefact sans responsabilité explicite.
C’est particulièrement dangereux dans les entreprises qui croissent rapidement.
Un pipeline naît pour répondre à un besoin local. Puis il alimente un tableau de bord. Plus tard, il devient une source pour un rapport exécutif. À un moment donné, il alimente également un modèle de recommandation ou un processus d’IA. Or personne n’a réexaminé le contrat initial, car peut-être qu’il n’a jamais existé.
À partir de là, tout changement peut casser des consommateurs invisibles.
Donner comme produit n’est pas un discours joli. C’est une façon de dire qu’un ensemble de données a des utilisateurs, une attente de qualité, une responsabilité et un cycle de vie.
Sans propriété, il n’existe pas de produit de données. Il existe un fichier partagé avec plus d’infrastructures.
Lakehouse et warehouse restent importants, mais ne constituent pas la première question
Il ne s’agit pas de diminuer l’importance de l’architecture de la plateforme.
Les warehouses restent excellents pour de nombreux scénarios analytiques, avec une modélisation structurée, des requêtes cohérentes et une forte intégration avec BI. Les lakehouses apportent des avantages importants lorsque l’on doit gérer des données structurées, semi-structurées, à l’échelle, la science des données, l’IA et la flexibilité de stockage.
Le choix compte.
Mais il devrait venir après des questions plus fondamentales :
- Quels domaines produisent des données critiques ?
- Qui consomme ces données ?
- Quels datasets devraient être traités comme un produit ?
- Quelles contrats soutiennent ces consommations ?
- Où la sémantique doit-elle être standardisée ?
- Quelles données alimentent la décision stratégique ou l’IA ?
Sans cela, la discussion lakehouse vs warehouse devient un débat d’architecture dépourvu de base de consommation.
C’est comme choisir le type de route avant de savoir quelles villes ont besoin d’être reliées.
Pourquoi les contrats de données prennent encore plus d’importance avec l’IA
L’essor de l’IA, du RAG, des agents et des copilotes d’entreprise augmente considérablement le coût des mauvaises données.
Lorsqu’un tableau de bord utilise une métrique mal définie, le problème est déjà sérieux. Lorsqu’un modèle ou un agent utilise des données mal définies, obsolètes ou hors contexte, le risque s’accroît encore davantage.
Un système d’IA peut répondre avec assurance en utilisant :
- Un document ancien
- Un champ sans signification claire
- Une base dupliquée
- Des informations sans propriétaire
- Des données sans lignage
- Du contenu hors contexte
Le résultat peut sembler sophistiqué, mais être incorrect.
Dans les architectures avec RAG, par exemple, la qualité de la réponse dépend directement de la qualité, de l’actualité et de la sémantique de la base consultée. Si l’organisation ignore qui est le propriétaire du contenu, quand il a été mis à jour, quelle version est valable et quel contexte doit accompagner la donnée, le modèle hérite de la confusion.
L’IA ne corrige pas l’absence de gouvernance des données. Elle l’amplifie.
C’est pourquoi les contrats de données et les contrats de connaissance tendent à devenir encore plus importants dans les environnements d’affaires qui adoptent l’IA de manière sérieuse.
Le contrat n’est pas de la bureaucratie, c’est la protection du consommateur
Le mot contrat peut sembler lourd. Mais l’objectif n’est pas de bureaucratiser tout le dataset de l’entreprise. L’objectif est de protéger les consommateurs des données critiques.
Tout n’a pas besoin du même niveau de rigueur.
Un dataset exploratoire peut avoir un contrat léger. Un dataset qui alimente la clôture financière, le pricing, le modèle de crédit, la recommandation ou une décision exécutive nécessite beaucoup plus de clarté.
Le secret réside dans la classification de la criticité.
Questions utiles :
- Cette donnée alimente-t-elle une décision stratégique ?
- Cette donnée est-elle utilisée par plus d’une équipe ?
- Cette donnée impacte-t-elle le client final ?
- Cette donnée alimente-t-elle l’IA ou l’automatisation ?
- Une rupture dans cette donnée causerait-elle un incident, une retouche ou une décision erronée ?
Plus les réponses sont « oui », plus le contrat est nécessaire.
Ce qui change lorsque la donnée est traitée comme un produit
Traiter la donnée comme un produit modifie le comportement de l’équipe responsable.
L’objectif cesse d’être uniquement de « livrer une table » et devient de fournir une expérience de consommation fiable.
Cela comprend :
- Une documentation claire
- Un propriétaire visible
- Un schéma stable
- Version et changelog
- Tests de qualité
- Attente de mise à jour
- Communication des changements
- Retour des consommateurs
Remarquez la similitude avec les APIs. Une API mature n’est pas seulement un point d’extrémité. Un dataset mature n’est pas seulement une table.
Les deux sont des contrats de consommation.
Et, dans les deux cas, la maturité se manifeste lorsque celui qui publie assume la responsabilité de l’expérience de celui qui consomme.
Un cadre simple pour évaluer la maturité des données
Si l’objectif est de sortir de la théorie, ces questions aident énormément.
1. Qui est le propriétaire de ce dataset ?
Si personne ne répond de la qualité et de l’évolution, le risque a déjà commencé.
2. Qui consomme ces données ?
Des consommateurs invisibles rendent toute modification dangereuse.
3. Que signifie chaque champ ?
Le nom d’une colonne n’est pas une documentation suffisante. Sans sémantique, la donnée devient interprétation.
4. Quelle est l’attente de mise à jour ?
Des données retardées peuvent être pires que l’absence de données, surtout lorsque les décisions en dépendent.
5. Qu’est-ce qui est considéré comme une rupture ?
Supprimer un champ, changer le type, modifier la signification, changer la règle de calcul, retarder la mise à jour. Tout cela peut rompre les consommateurs.
6. Les changements sont-ils communiqués ?
Sans avertissement, chaque modification devient une surprise opérationnelle.
7. Existe-t-il une surveillance de la qualité ?
Un contrat sans validation devient un document oublié.
Ces questions sont simples, mais elles changent la conversation. Elles déplacent l’attention de l’outil vers la relation entre le producteur et le consommateur.
La séniorité apparaît lorsque l’équipe cesse d’idolâtrer la pile
Les professionnels seniors savent que l’outil compte. Mais ils savent aussi que l’outil ne suffit pas face à l’absence de clarté.
Une architecture de données mature ne naît pas simplement parce que l’entreprise a adopté un lakehouse, un warehouse moderne, un catalogue ou un moteur distribué. Elle naît lorsqu’il existe une compréhension du domaine, de la propriété, de la sémantique, de la qualité et de la consommation.
La stack doit servir ce dessin. Elle ne doit pas le remplacer.
= »Lorsque l’organisation inverse cet ordre, elle donne l’illusion d’une évolution. Tout paraît plus moderne, mais les problèmes de confiance restent là.
Conclusion
Le choix entre lakehouse et warehouse peut être important. Mais, dans de nombreuses entreprises, ce n’est pas la première question qu’il faudrait poser.
Avant de discuter où stocker, traiter ou consulter les données, il faut comprendre qui en dépend, ce que cela signifie, qui est responsable et quel contrat soutient cette consommation.
Sans cela, même la plateforme la plus moderne ne sera qu’une couche supplémentaire sur des données peu fiables.
Les données maturées ne sont pas seulement des données disponibles. Ce sont des données compréhensibles, fiables, gouvernées et soutenues par un contrat.
Revisitez qui publie, qui consomme et où les contrats de données sont réellement explicites dans votre environnement.

