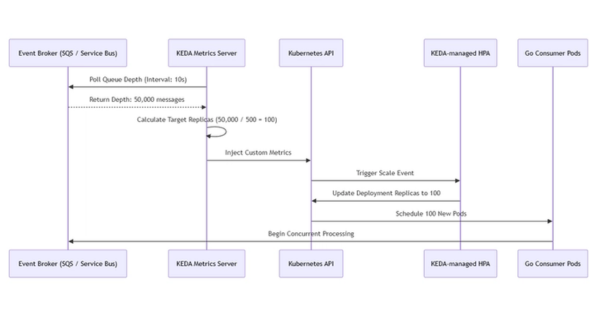
Des charges de travail d’ingestion de données imprévisibles et de volume élevé exposent les limites fondamentales des auto‑échelles horizontales de pods (HPA) nativement intégrées à Kubernetes. Lorsqu’un système reçoit un afflux soudain de millions de payloads à traiter en temps réel, s’appuyer sur l’utilisation du processeur ou de la mémoire comme déclencheurs d’escalade devient un indicateur de retard important. La couche de calcul reste sous‑dimensionnée pendant que la profondeur de la file d’attente s’emballe, entraînant des retards de traitement inacceptables et, potentiellement, l’expiration des messages. Nous avons résolu ce goulet d’étranglement opérationnel en déployant Kubernetes Event-driven Autoscaling (KEDA) dans une architecture multicloud. En isolant les métriques d’escalade du hyperviseur et en les reliant directement à des sources d’événements externes, telles que Amazon SQS ou Azure Service Bus, KEDA permet d’ajuster dynamiquement des déploiements de consommateurs Go isolés, passant de zéro à des milliers de pods en quelques secondes. Cette architecture garantit que la capacité de traitement corresponde exactement à l’indicateur de demande, assurant une exécution haute performance sur AWS et sur Microsoft Azure, tout en réduisant les coûts de calcul inactif à zéro absolu.
Pré-requis
La mise en place d’un maillage d’escalade orienté événement exige une connaissance approfondie des ressources personnalisées de Kubernetes ainsi que de la conception d’applications fortement concurrents. Le provisioning de l’infrastructure nécessite Terraform version 1.7.0 ou supérieure, en intégrant les fournisseurs HashiCorp AWS, AzureRM et Helm. Les clusters Kubernetes doivent être exécutés avec la version 1.29 ou supérieure sur Amazon EKS et Azure AKS, avec KEDA version 2.14 installée nativement via Helm. La logique de consommation fortement concurrente requiert Go 1.22, en utilisant des définitions d’interfaces strictes afin de répondre aux contraintes de l’Architecture Hexagonale. Une fédération OpenID Connect (OIDC) doit être activée pour permettre aux opérateurs KEDA de s’authentifier de manière sécurisée auprès des API de métriques des fournisseurs de cloud.
Implémentation étape par étape
Mise en place de la limite d’escalade orientée par les métriques
Nous avons établi une capacité de calcul réactive en déployant un KEDA ScaledObject directement dans les espaces de noms Kubernetes qui hébergent nos consommateurs. La justification architecturale pour remplacer le HPA standard par un ScaledObject de KEDA réside dans la précision d’escalade déterministe. Plutôt que d’attendre qu’un pod atteigne une saturation CPU, KEDA interroge en continu le broker de messages externe. Nous avons configuré les règles d’escalade pour évaluer précisément l’arriéré des partitions de données en attente. Si la profondeur de la file dépasse une limite prédéfinie, KEDA intercepte l’API d’escalade de Kubernetes et provisionne préventivement de nouveaux pods avant qu’un manque de CPU n’apparaisse. En fixant une limite d’escalade déterministe minReplicaCount: 0, nous garantissons que toute l’infrastructure de calcul du consommateur puisse être réduite à zéro absolu durant les périodes creuses, préservant le budget de calcul multicloud pour les charges actives et génératrices de revenus.
# KEDA ScaledObject defining queue-based autoscaling for an EKS cluster
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: data-processor-scaler
namespace: enterprise-processing
spec:
scaleTargetRef:
name: go-parquet-processor
pollingInterval: 10
cooldownPeriod: 300
minReplicaCount: 0
maxReplicaCount: 250
triggers:
- type: aws-sqs-queue
authenticationRef:
name: keda-aws-credentials
metadata:
queueURL: https://sqs.us-east-1.amazonaws.com/123456789012/multicloud-ingestion-queue
queueLength: "500"
awsRegion: "us-east-1"
Lorsque la couche de calcul passe brutalement de zéro à deux cents pods simultanés, comment pouvons-nous garantir que le code de l’application demeure totalement isolé de la technologie de mise en file d’attente utilisée, évitant ainsi une dépendance envers un seul fournisseur ?
Désaccoupler le mécanisme d’ingestion par le biais d’interfaces Go
Nous garantissons une portabilité absolue vers le cloud en concevant le consommateur Go selon un cadre hexagonal rigoureux, définissant le mécanisme d’ingestion d’événements strictement par le biais d’interfaces. Le besoin architectural ici est d’empêcher que les paquets aws-sdk-go-v2 du SDK AWS ou les paquets du SDK Azure n’interfèrent avec la logique métier centrale. Lors du traitement de formats à forte densité, tels que les fichiers Parquet, la logique métier doit rester pure. Nous avons construit une porte EventReceiver qui définit un contrat pour récupérer et confirmer les messages. La couche d’infrastructure implémente cette interface avec une SQSAdapter pour les déploiements sur AWS EKS et une ServiceBusAdapter pour les déploiements sur Azure AKS. Les goroutines principales fonctionnent indépendamment de l’interface, créant des goroutines légères pour traiter la charge utile en mémoire, garantissant que la migration d’un worker hautement concurrent d’AWS vers Azure n’exige aucune modification de la logique métier.
package main
import (
"context"
"fmt"
"log"
"sync"
)
// Inbound Port: Shields domain from vendor-specific message brokers
type EventReceiver interface {
Receive(ctx context.Context) (<-chan []byte, error)
Acknowledge(ctx context.Context, messageID string) error
}
// Core Domain Service
type DataProcessorService struct {
receiver EventReceiver
}
func NewDataProcessorService(r EventReceiver) *DataProcessorService {
return &DataProcessorService{receiver: r}
}
func (s *DataProcessorService) StartProcessing(ctx context.Context, workers int) {
messages, err := s.receiver.Receive(ctx)
if err != nil {
log.Fatalf("Failed to initialize event receiver: %v", err)
}
var wg sync.WaitGroup
for i := 0; i < workers; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Printf("Worker %d shutting down gracefully.n", workerID)
return
case payload, ok := <-messages:
if !ok {
return
}
// Pure domain execution, agnostic of AWS or Azure origins
s.processPayload(payload)
}
}
}(i)
}
wg.Wait()
}
func (s *DataProcessorService) processPayload(payload []byte) {
// High-performance parsing and domain logic execution
_ = payload
}
Si la logique métier est complètement découplée et que les pods parviennent à extraire des milliers de messages simultanément, qu’est‑ce qui empêche ce pic massif et instantané de concurrence d’engorger et de provoquer l’effondrement des bases de données relationnelles en aval ?
Imposition de limites de concurrence et regroupement des connexions
Nous protégeons les systèmes en aval contre une surcharge catastrophique en mettant en place un contrôle rigoureux de la concurrence et des pools de connexions limités dans les adaptateurs d’infrastructure. Bien que KEDA résolve le problème d’évolutivité du calcul, l’évolution vers deux cents pods, chacun exécutant cinquante goroutines, génère dix mille connexions simultanées à la base de données. Ce phénomène épuise instantanément les seuils de connexion d’Amazon RDS ou de la base de données PostgreSQL sur Azure, entraînant des timeouts et des pertes de transactions. La couche d’infrastructure Go doit mettre en œuvre une multiplexage des connexions en utilisant le package database/sql et les appels SetMaxOpenConns et SetMaxIdleConns. De surcroît, nous encapsulons les opérations d’écriture en aval dans un motif de sémaphore localisé à l’aide de canaux avec tampon. Cette configuration restreint le nombre maximal d’appels réseau sortants simultanés par pod, garantissant que l’application optimise l’utilisation du CPU pour la transformation des données tout en maintenant un débit prévisible et sûr à la couche de persistance.
package infrastructure
import (
"context"
"database/sql"
"time"
)
type PostgresRepository struct {
db *sql.DB
semaphore chan struct{}
}
func NewPostgresRepository(dsn string, maxConnections int) (*PostgresRepository, error) {
db, err := sql.Open("postgres", dsn)
if err != nil {
return nil, err
}
// Strictly bound the connection pool to prevent downstream exhaustion
db.SetMaxOpenConns(maxConnections)
db.SetMaxIdleConns(maxConnections / 2)
db.SetConnMaxLifetime(time.Minute * 30)
return &PostgresRepository{
db: db,
// Semaphore limits concurrent execution paths attempting to write
semaphore: make(chan struct{}, maxConnections),
}, nil
}
func (r *PostgresRepository) PersistResult(ctx context.Context, data []byte) error {
// Block until a semaphore slot is available
r.semaphore <- struct{}{}
defer func() { <-r.semaphore }()
query := `INSERT INTO processed_data (payload, created_at) VALUES ($1, NOW())`
_, err := r.db.ExecContext(ctx, query, data)
return err
}Dépannage courant
Lors du déploiement de KEDA dans des environnements multicloud, les échecs d’authentification d’intégration constituent l’obstacle le plus persistant. Si l’opérateur KEDA ne parvient pas à récupérer les métriques et que votre ressource HPA Kubernetes affiche <unknown> avec les métriques actuelles, TriggerAuthentication est probablement mal configuré. Sur AWS EKS, vérifiez que le rôle IAM pour les comptes de service (IRSA) accorde les permissions spécifiquement sqs:GetQueueAttributes au compte de service exact utilisé par l’opérateur KEDA, et pas seulement aux pods de l’application. Sur Azure AKS, vérifiez que les identités fédérées mappent correctement l’enregistrement de l’application Azure AD au namespace et au compte de service de KEDA.
Autre problème opérationnel grave qui survient lors des événements de réduction d’échelle quand on traite des tâches de données de longue durée : si KEDA détermine que la file est vide, il arrête rapidement les pods. Si l’application Go ne capte pas le signal SIGTERM, les goroutines actives seront brutalement terminées, ce qui peut corrompre les données en transit et faire perdre des messages non confirmés. Vous devez mettre en place des canaux d’actualité os.Signal dans votre fichier main.go, capturer le signal d’arrêt et déclencher une annulation de contexte qui permet aux groupes d’attente des workers de terminer de traiter leurs charges utiles actuelles avant que le conteneur ne soit arrêté.
Conclusion
La fédération entre KEDA et Go sur AWS EKS et Azure AKS établit un mécanisme de traitement extraordinairement résilient et économique, capable de gérer des volumes de données imprévisibles. En découplant les métriques d’escalade de la performance interne du cluster et en imposant des limites architecturales hexagonales, les équipes d’ingénierie s’assurent que la logique applicative demeure instantanément portable sur des infrastructures de fournisseurs mondiaux. Pour renforcer encore ce pipeline, les organisations devraient explorer l’intégration de KEDA avec les métriques Prometheus générées directement par l’application Go. Cette évolution permet au mécanisme d’escalade de réagir non seulement à la profondeur de la file externe, mais aussi à la latence de traitement interne de l’application, fournissant une matrice d’évolutivité multidimensionnelle parfaitement équilibrée.

