Ces derniers jours, j’avais besoin de tester Kafka Connect pour un scénario d’ingestion de données et je me suis dit : pourquoi ne pas monter un laboratoire simple qui soit pertinent pour d’autres projets ?
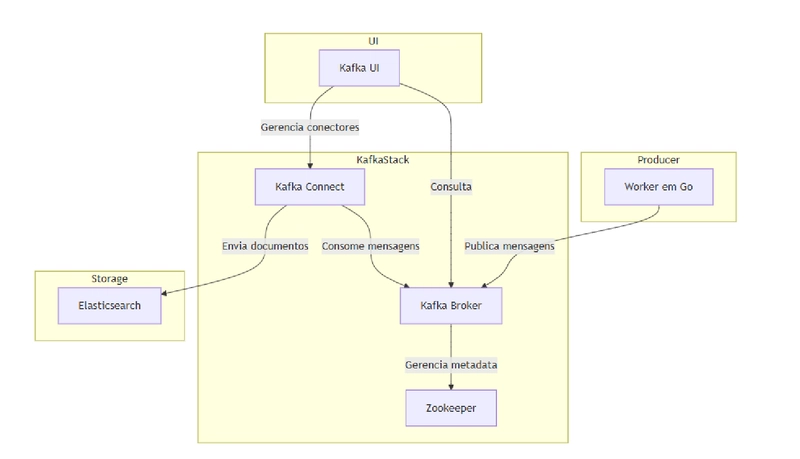
L’idée était limpide :
- Un producteur en Go qui interroge l’API de Binance et envoie des messages vers Kafka.
- Kafka Connect qui consomme ce topic et déverse les messages dans Elasticsearch.
- Kafka UI pour inspector ce qui se passe sur les topics.
Tout cela tournant dans des containers avec Docker Compose, parce que personne n’a envie de tout configurer à la main.
Envie d’apprendre comment faire ? Allons-y !
Ce que nous allons construire
Notre flux de données sera le suivant :
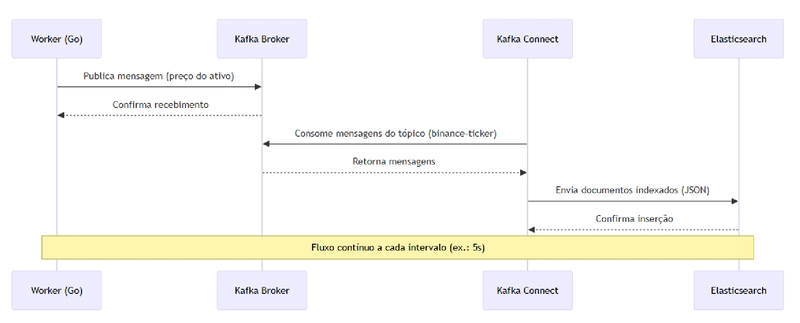
Et nous ajouterons le Kafka UI pour faciliter la visualisation.
Étape 1 – Structure du projet
Créez un dossier pour le projet :
mkdir kafka-connect-lab
cd kafka-connect-labStructurez-le ainsi :
kafka-connect-lab/
├── cmd/worker/ # Code Go du producer
│ └── main.go
├── Dockerfile # Dockerfile du worker
├── docker-compose.yml # Orchestration
└── go.mod # Module GoInitialisez le module Go :
go mod init github.com/seuprojeto/kafka-connect-lab
go get github.com/segmentio/kafka-goÉtape 2 – Écriture du Worker en Go
Nous allons créer un producteur qui interroge le prix du Bitcoin sur Binance et le publie dans Kafka.
Le code complet :
Ouvrez cmd/worker/main.go :
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"net/http"
"os"
"time"
kafka "github.com/segmentio/kafka-go"
)👉 Qu’est-ce que nous avons ici ?
- Nous importons des paquets de base (
log,os,time, etc.). - Nous importons la librairie
kafka-gopour nous connecter à Kafka.
type Ticker struct {
Symbol string `json:"symbol"`
Price string `json:"price"`
}👉 Pourquoi cette structure ?
Elle représente le JSON que nous recevons de l’API de Binance, avec paire de négociation et prix.
func fetchTicker(symbol string) (*Ticker, error) {
url := "https://api.binance.com/api/v3/ticker/price?symbol=" + symbol
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("erro Binance: %d", resp.StatusCode)
}
var t Ticker
if err := json.NewDecoder(resp.Body).Decode(&t); err != nil {
return nil, err
}
return &t, nil
}👉 Que fait cette fonction ?
- Construit l’URL vers Binance.
- Réalise une requête HTTP GET.
- Découpe la réponse JSON directement dans la structure
Ticker. - Retourne un pointeur vers
Ticker.
Maintenant, la fonction main() :
func main() {
broker := os.Getenv("KAFKA_BROKER")
topic := os.Getenv("KAFKA_TOPIC")
symbol := os.Getenv("BINANCE_SYMBOL")
if symbol == "" {
symbol = "BTCUSDT"
}
interval := os.Getenv("FETCH_INTERVAL")
if interval == "" {
interval = "5s"
}
d, err := time.ParseDuration(interval)
if err != nil {
log.Fatalf("Intervalle invalide : %v", err)
}
👉 Que faisons-nous ici ?
- Nous lisons les configurations via des variables d’environnement.
- Si rien n’est passé, nous utilisons des valeurs par défaut (
BTCUSDTet un intervalle de5s).
writer := kafka.NewWriter(kafka.WriterConfig{
Brokers: []string{broker},
Topic: topic,
Balancer: &kafka.LeastBytes{},
})
defer writer.Close()
log.Printf("Worker démarré. Broker=%s, Tópico=%s, Actif=%s", broker, topic, symbol)
👉 Ici nous initialisons le Producteur :
NewWritercrée un writer pour envoyer des messages à Kafka.- Nous utilisons le répartiteur
LeastBytespour distribuer les messages (idéal même dans des clusters).
ticker := time.NewTicker(d)
defer ticker.Stop()
for range ticker.C {
data, err := fetchTicker(symbol)
if err != nil {
log.Println("Erreur lors de la récupération du ticker :", err)
continue
}
msg, _ := json.Marshal(data)
err = writer.WriteMessages(context.Background(), kafka.Message{Value: msg})
if err != nil {
log.Println("Erreur lors de la publication :", err)
} {
log.Printf("Message publiée : %s = %s", data.Symbol, data.Price)
}
}
}
👉 La boucle principale :
- Elle s’exécute toutes les
intervalsecondes. - Interroge le prix sur Binance.
- Sérialise en JSON.
- Publie dans Kafka.
Résultat : Toutes les 5 secondes, le prix du BTC est publié sur le topic.
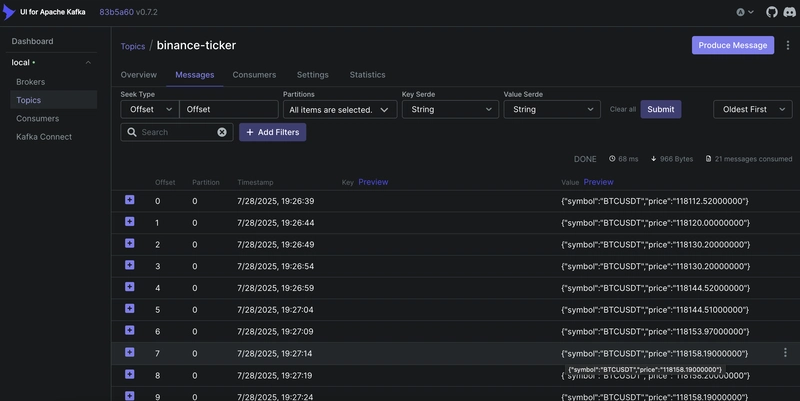
Étape 3 – Emballer avec Docker
Créez un fichier Dockerfile à la racine :
# construction
FROM golang:1.20-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY cmd/worker ./cmd/worker
RUN go build -o worker ./cmd/worker
# runtime
FROM alpine:latest
WORKDIR /app
COPY --from=builder /app/worker ./
RUN apk add --no-cache ca-certificates
ENTRYPOINT ["./worker"]👉 Pourquoi le multi-stage ?
- La première image compile le binaire.
- La seconde ne charge que l’exécutable final, léger et rapide.
Étape 4 – Orchestrer le tout avec Docker Compose
Créez le fichier docker-compose.yml :
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.7.4
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:7.7.4
depends_on: [zookeeper]
ports: ["9092:9092"]
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.28
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms512m -Xmx512m
ports: ["9200:9200"]
kafka-connect:
image: confluentinc/cp-kafka-connect:7.7.4
depends_on: [kafka]
ports: ["8083:8083"]
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:9092
CONNECT_GROUP_ID: connect-cluster
CONNECT_CONFIG_STORAGE_TOPIC: connect-config
CONNECT_OFFSET_STORAGE_TOPIC: connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: connect-status
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: 'false'
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: 'false'
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components
command:
- bash -c
- |
confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:13.0.0
/etc/confluent/docker/run
worker:
build: .
depends_on: [kafka]
environment:
KAFKA_BROKER: kafka:9092
KAFKA_TOPIC: binance-ticker
BINANCE_SYMBOL: BTCUSDT
FETCH_INTERVAL: 5s
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
depends_on: [kafka, kafka-connect]
ports: ["8080:8080"]
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: connect
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-connect:8083👉 Qu’avons-nous ici ?
- Kafka + Zookeeper.
- Elasticsearch (pour accueillir les données).
- Kafka Connect (déjà avec le connecteur vers ES).
- Worker Go.
- Kafka UI pour faciliter le débogage.
Étape 5 – Déployer tout
docker-compose up --buildSi Elasticsearch réclame de la mémoire :
sudo sysctl -w vm.max_map_count=262144
Étape 6 – Création du topic
docker-compose exec kafka kafka-topics --create \
--topic binance-ticker \
--bootstrap-server kafka:9092 \
--replication-factor 1 \
--partitions 1Étape 7 – Configuration du connecteur
Voici maintenant l’étoile du spectacle : Kafka Connect.
curl -X POST -H "Content-Type: application/json" \
--data '{
"name": "es-sink",
"config": {
"connector.class":"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max":"1",
"topics":"binance-ticker",
"connection.url":"http://elasticsearch:9200",
"type.name":"_doc",
"key.ignore":"true",
"schema.ignore":"true"
}
}' http://localhost:8083/connectorsVous voulez savoir s’il est monté ?
curl http://localhost:8083/connectors/es-sink/status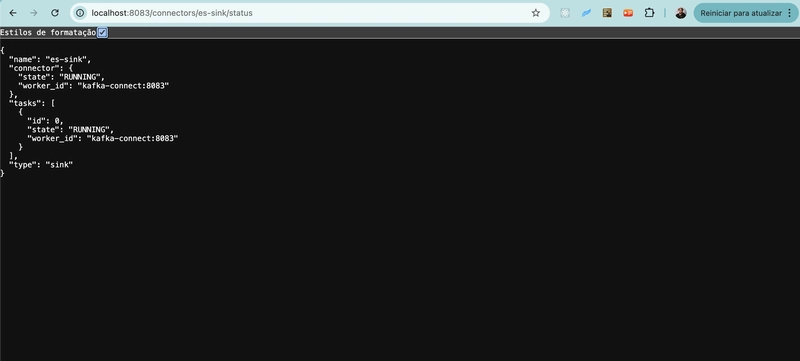
Étape 8 – Tester le tout
- Rendez-vous dans le Kafka UI : http://localhost:8080 → observez le topic
binance-tickerrecevoir des messages. - Interrogez Elasticsearch :
curl http://localhost:9200/binance-ticker/_search?prettySortie attendue :
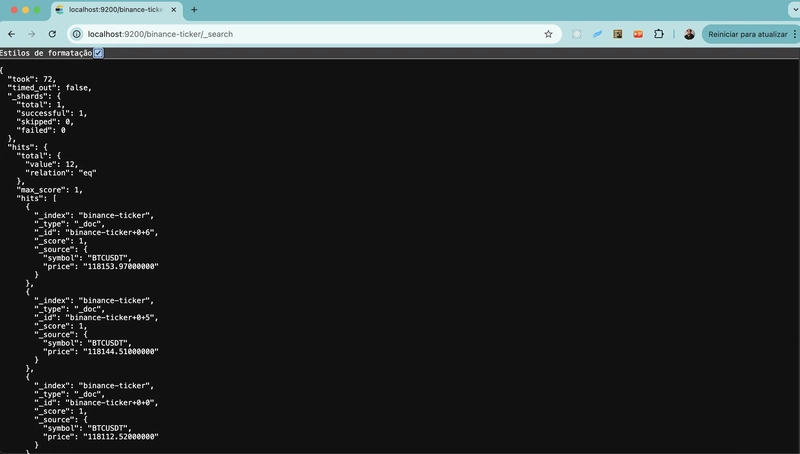
Prêt. Kafka Connect fonctionne !
Conclusion
Dans cet article, nous avons construit un laboratoire complet pour tester Kafka Connect :
- Nous avons créé un worker en Go qui exploite l’API de Binance et publie dans Kafka.
- Nous avons déployé un environnement incluant Kafka, Kafka Connect, Elasticsearch et Kafka UI via Docker Compose.
- Nous avons configuré un connecteur Elasticsearch dans Kafka Connect pour consommer les messages et les indexer automatiquement.
- Nous avons validé le pipeline via Kafka UI et des requêtes REST sur Elasticsearch.
Cet environnement est un excellent point de départ pour tester d’autres connecteurs, expérimenter des transformations et comprendre le flux de données dans des architectures orientées événements.
Comme prochaines étapes, vous pouvez :
- Ajouter Kibana pour des visualisations.
- Créer un cluster Kafka avec plusieurs brokers.
- Activer TLS et authentification, afin de rapprocher le setup d’un environnement de production.
Références
Apache Software Foundation. (2024). Kafka Connect documentation. https://kafka.apache.org/documentation/#connect
Confluent, Inc. (2024). Confluent Hub. https://www.confluent.io/hub/
Elastic. (2024). Elasticsearch REST API documentation. https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
LuizTools. (2023). Introduction au Kafka et comment l’utiliser avec Node.js. https://luiztools.com.br/kafka-com-nodejs
Segment.io. (2024). kafka-go: Apache Kafka client for Go. https://github.com/segmentio/kafka-go
Lectures complémentaires
- LuizTools – Introduction au Kafka et comment l’utiliser avec Node.js
- Confluent – Building Data Pipelines with Kafka Connect
- Elastic – Ingestão de datos com Kafka + Elasticsearch
- Go by Example – Travailler avec JSON en Go

