Dans le billet précédent, j’ai brièvement expliqué comment fonctionne une architecture orientée événements et comment nous avons implémenté cette architecture chez Convenia. J’ai évoqué un peu notre traitement des erreurs et aujourd’hui je compte approfondir ce sujet.
Tout comme dans le post précédent, je tiens à souligner que les choix d’architecture et de stack ont du sens pour notre taille et nos prévisions de croissance. Il est possible que pour vous, tout faire exactement comme nous ne fasse pas sens, car chaque projet est unique avec ses particularités; néanmoins il est probable que vous puissiez retirer quelque chose de positif de ce post.
Dans ce post, les mots « message » et « événement » représentent la même chose mais dans des contextes différents. Grosso modo, « message » désigne l’information en transit via un broker de messages, et « événement » désigne le nom donné au même message dans un contexte « orienté événements ». Le terme « listener » est utilisé pour décrire le processus chargé d’« écouter » les événements.
Comment les services communiquent-ils ?
Pour illustrer, prenons l’exemple simple avec Pigeon, très proche de celui du post précédent :
Pigeon::dispatch('employee.created', [
'name' => 'Scooby Doo'
]);Dans l’exemple ci-dessus, nous émettons l’événement employee.created dont le corps contient le nom du collaborateur. Pour écouter cet événement dans un autre service à l’aide de Pigeon, on utilise ce code :
Pigeon::events('employee.created')
->callback(function ($event, ResolverContract $resolver) {
//faire des choses utiles
$resolver->ack();
})->
fallback(Throwable $exception, $message, $resolver) {
//envoyer vers Sentry
$resolver->reject(false);
})->
consume(0, true);Le code ci-dessus accomplit plusieurs choses
- Configure Pigeon pour écouter l’événement
employee.createddans un autre service, via l’appelPigeon::events('employee.created'). - Définit un callback pour « traiter » l’événement en passant une Closure par la méthode
->callback(); cette Closure sera exécutée à chaque fois que l’événementemployee.createdest « entendu ». - Définit un fallback via la méthode
->fallback(); cette closure sera exécutée dès qu’une exception survient dans le callback. - La méthode
->consume()démarre effectivement la consommation de la file.
Le Pigeon utilise RabbitMQ comme intermédiaire de communication entre les deux services; si l’on essaie de représenter cela dans un diagramme, on obtient le schéma suivant :
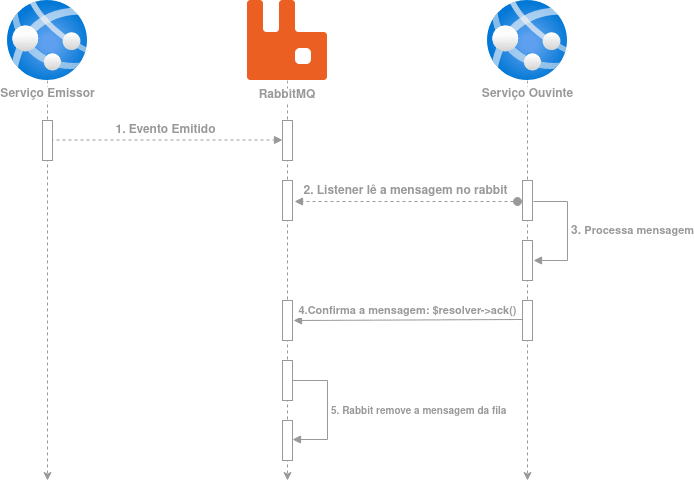
Au moment où le service lit le message depuis RabbitMQ, celui-ci reste dans un état « unacked » (non reconnu). Cela signifie que RabbitMQ attend la confirmation de celui qui a lu le message. RabbitMQ ne livrera pas ce message à quelqu’un d’autre tant qu’il n’aura reçu ni la confirmation que tout s’est bien passé, ni la confirmation d’échec (rejet) du message. À l’étape 4 décrite dans le diagramme, nous envoyons une accusation au RabbitMQ pour lui indiquer que le traitement s’est correctement déroulé; ce n’est qu’après cette confirmation que RabbitMQ retire le message de la file.
Le diagramme ci-dessus illustre un parcours tout à fait heureux, mais imaginons que juste après la lecture du message, le listener tombe en panne en raison d’un problème matériel avant de confirmer le traitement :
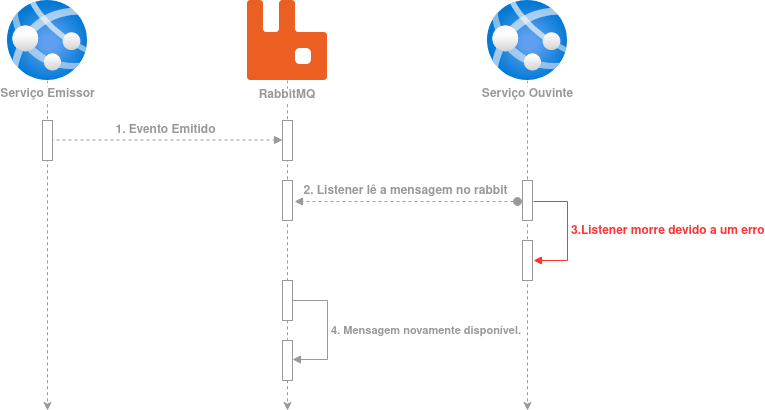
De manière similaire à l’exemple précédent, après la lecture du message Rabbit le place dans l’état « unacked ». Si un coût très inattendu survient et que le listener (le processus) meurt à l’étape 3, Rabbit saura alors qu’il doit remettre le message dans l’état « ready ». Ainsi, un autre listener peut tenter à son tour de traiter ce même message. Cela est possible parce que les listeners maintiennent une connexion ouverte avec Rabbit et lorsque le processus du listener meurt, la connexion est « coupée ». À ce moment-là, Rabbit sait qu’il doit « libérer » toutes les messages que ce listener a lus mais n’a pas confirmés.
Nous avons jusqu’à présent décrit des flux sains et des défaillances tierces qui peuvent se produire de manière sporadique. Mais que se passe-t-il lorsque notre propre code qui consomme le message est cassé ? Et lorsque le message lui-même est corrompu ?
Dead Letter Exchange pour le secours
Imaginons la situation où le code de notre propre listener est cassé :
Pigeon::events('employee.created')->callback(function ($event, ResolverContract $resolver) {
doesNotExists();
$resolver->ack();
})->consume(0, true);Dans le code ci-dessus, notez l’appel à la fonction doesNotExists(); comme son nom l’indique, cette fonction n’existe pas et lorsque ce listener essaie de consommer un message, il bascule dans le flux illustré à la figure 2. Le problème majeur est que l’on utilise généralement un outil comme supervisord pour « relancer » les processus qui meurent et lorsque ce listener « revient à la vie », il va retomber dans le flux de la figure 2, entraînant une boucle infinie.
On se retrouve avec un message consommé en boucle; il ne sera correctement consommé que si le code du listener est corrigé. Cela engendre plusieurs problèmes comme évoqué dans le post précédent. RabbitMQ dispose justement d’une fonctionnalité appelée dead letter exchange (échange de lettres mortes) qui sert ce genre de situation et qui permet d’envoyer le message vers une exchange séparée pour un traitement ultérieur. Le flux suivant montre ce mécanisme :
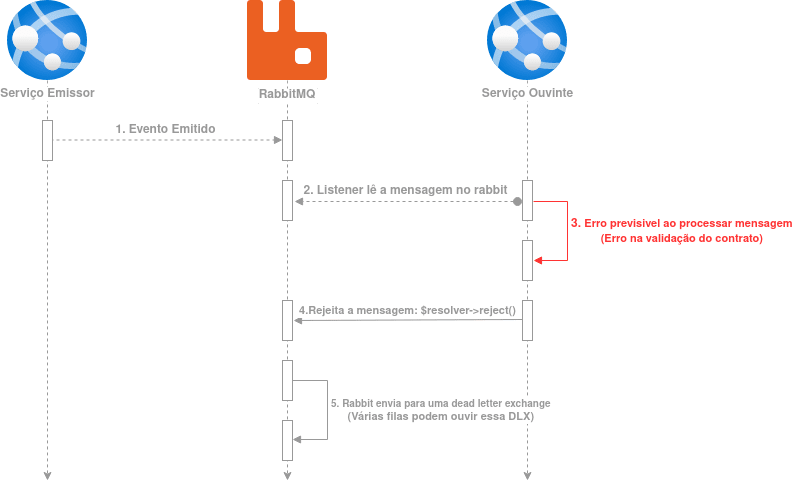
Pour que ce flux puisse se réaliser, il faut « rejeter » explicitement le message via la méthode fallback présentée au début de l’article et illustrée à nouveau ci-après :
->fallback(Throwable $exception, $message, $resolver) {
//envoyer vers Sentry
$resolver->reject(false);
})Dans le code ci-dessus, l’appel $resolver->reject(false); est la commande qui rejette explicitement le message. Si vous ne définissez pas de fallback, Pigeon dispose d’un fallback par défaut qui rejettera le message si l’environnement PIGEON_ON_FAILURE est présent avec la valeur reject.
LetterThief
Après avoir rejeté le message, celui-ci est envoyé vers une dead letter exchange où l’on peut stocker ce message problématique dans une file, l’évaluer ultérieurement ou lui appliquer un traitement adapté sur place. Chez Convenia, nous avons développé un service appelé « LetterThief » qui est chargé de gérer les messages qui ont été rejetés et d’avertir l’équipe lorsque survient un rejet :
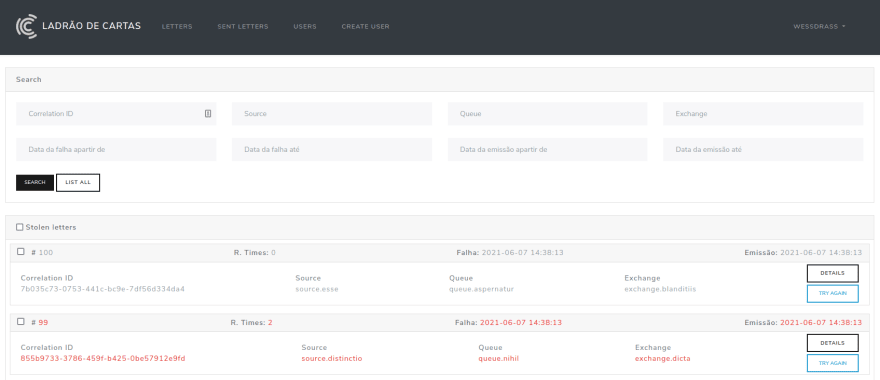
Ci-dessus se trouve la liste des messages rejetés. Dans ce service, nous pouvons filtrer les messages par leurs propriétés. Chaque rejet se produit dans une file et une exchange spécifiques et à un moment donné. Les filtres permettent de faire apparaître les rejets qui ont lieu dans une file précise ou à un moment donné.
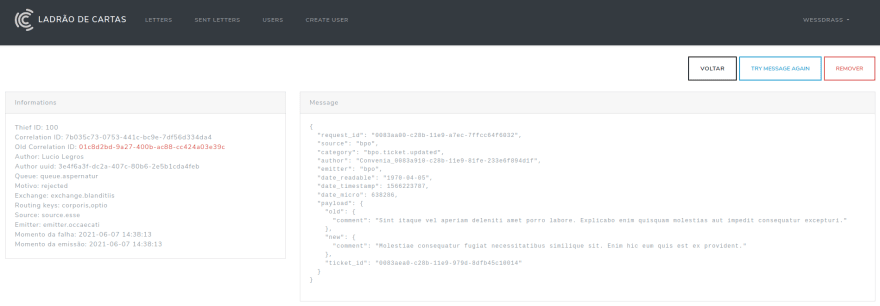
Sur la page de détails de la message rejetée, nous retrouvons toutes les informations associées : de quel service elle provient, quel listener l’a rejetée et, plus important, le correlation_id qui sera utilisé pour mettre en correspondance l’erreur avec les exceptions qui remontent dans Sentry. Avec ces informations, nous savons exactement pourquoi une message a été rejetée et l’envoi vers Sentry est effectué par le listener juste avant le rejet:


Les images ci-dessous illustrent une erreur réelle survenue en production et la partie des tags contenant le correlation_id; malheureusement, je ne peux pas afficher l’exception avec davantage de détails pour ne pas exposer des données sensibles :/
Intéressant : le service apporte une grande visibilité sur les erreurs survenues, mais comment les développeurs en sont-ils informés ? LetterThief s’intègre à Slack afin que toute l’équipe soit notifiée lorsqu’une erreur se produit et puisse agir immédiatement pour résoudre le problème.

Sur l’image ci-dessus, nous voyons la notification qui arrive sur Slack; elle contient la file où le problème s’est produit et le lien vers le message dans le service LetterThief, de sorte que le développeur responsable sache déjà qu’il doit corriger le problème au plus vite.
Vous vous demandez peut-être ce qui arrive au message une fois le problème corrigé, car il devrait potentiellement avoir un effet sur le système mais ne pas l’avoir eu en raison de l’erreur. Après la résolution, le développeur a la capacité de renvoyer le message via LetterThief.

Sur l’image ci-dessus, on peut voir le bouton « TRY MESSAGE AGAIN » qui donne lieu à cette confirmation affichée. Après confirmation, le message est renvoyé directement vers la file d’où l’erreur est partie, et le traitement devrait reprendre normalement.
Précautions supplémentaires
Vous êtes peut-être confronté à certaines questions après être arrivé jusqu’ici. En vérité, pour que tout cela fonctionne correctement, il faut adopter certaines précautions qui sont garanties par un processus rigoureux de revue de code :
- Les listeners doivent être idempotents. Comme une erreur peut survenir pendant le traitement — par exemple lors d’une création en base de données — il ne doit pas y avoir de doublons. Il faut préférer une opération d’upsert à un simple create, afin d’éviter que deux enregistrements soient créés lorsque le message est renvoyé; rappelons que le message peut être renvoyé plusieurs fois.
- Le listener doit obligatoirement envoyer le message à Sentry puis le rejeter immédiatement dans le fallback. Trop de logique n’est pas bienvenue ici, car il ne doit pas y avoir d’échecs dans le fallback : cela provoquerait le renvoi du message dans la file et le problème de réexécution infinie évoqué au début de ce post.
- Il faut faire attention à l’évaluation des dates dans le listener : il ne faut jamais évaluer le moment où le message arrive dans le listener, il faut toujours évaluer la date à laquelle l’événement a été émis — elle accompagne obligatoirement chaque événement —, afin d’éviter de traiter une date incorrecte due au décalage temporel du message.
Conclusion
Toute architecture distribuée s’accompagne d’une complexité accrue ; l’observabilité et la gestion des erreurs sont des sujets qui reviennent dans de nombreuses talks et préoccupent plusieurs équipes. Sans aucun doute, dans une architecture orientée événements, nous devons disposer d’un moyen efficace pour traiter les erreurs dans le traitement des messages asynchrones. Dans le cas spécifique de Convenia, la solution la plus adaptée a été de développer notre propre service répondant précisément à nos besoins. Il existe d’autres options de brokers de messages, comme Kafka, qui peuvent apporter des solutions prêtes à l’emploi pour ce problème, ce qui vous évitera de concevoir et de maintenir une solution vous-même. Dans tous les cas, il est très important de disposer d’une approche similaire pour aider l’équipe au quotidien.
LetterThief a été développé sur la base d’un principe de sécurité visant à prévenir toute perte de messages : si vous regardez attentivement, vous verrez qu’en utilisant LetterThief, il est impossible de perdre un message en cours de route; soit il est traité correctement, soit il est envoyé vers LetterThief. Si le développeur du listener a été particulièrement peu scrupuleux dans l’implémentation, le message reviendra dans la file; quelle que soit l’option choisie, cette prémisse de « ne jamais perdre le message » est essentielle à prendre en compte.
Article publié à l’origine ici et republicé sur iMasters à la demande de l’auteur.

